ユーザーインタビュー|北海道大学・和多和宏教授
このページでは、Humanome Eyes(以下「Eyes」)を実際にお使いいただいているユーザーの皆様へのインタビューをご紹介します。使ってみてどのように感じたか? など、率直な意見やご感想についてお伺いしています。
ご利用をお考えのお客様の参考になりますと幸いです。
お話しいただいた方

和多 和宏先生
北海道大学 大学院理学研究院 教授
東京医科歯科大学大学院医学系研究科 博士(医学)。米国デューク大学 医療センター 神経生物部門 リサーチアソシエイト、北海道大学 大学院先端生命科学研究院 准教授、北海道大学 大学院理学研究院 准教授(学内改組異動)を歴任。2021年10月より、北海道大学 大学院理学研究院 教授。音声発声学習を可能にする脳神経回路・メカニズムを物質・遺伝子レベルで明らかにすることを目的として、研究活動に従事。
インタビュー
小鳥の歌をAIで解析する
ヒューマノーム研究所(以下「HNL」):
本日はインタビューのお時間をありがとうございます。特に和多先生がEyesをどのように使っているのかや、研究内容について私たちが把握していないところも多いと思いますので、そのあたりをぜひお聞かせください。
和多先生(以下「和多」):
僕の研究は、小鳥のさえずりや歌を学習モデルとして、動物がどうやって他者の声を聞いて、発声パターンや声の出し方を真似ていくのかを、神経行動学的に研究しています。
学習臨界期と言うのですが、人の言語、言葉の獲得は非常に若い時にやりやすくて、年をとると難しくなっていく、ということが知られています。それがどのような神経メカニズムによって起こっているのかを研究しています。
HNL:
ちなみにEyesの利用はどのようなきっかけで検討いただけたのでしょうか。
和多:
AIによる画像認識によって、どれくらいまで声紋(声の特徴を機械によって分析した結果を模様化したもの、スペクトログラムともいう)の違いを認識できるのか?ということを試したかった、というのが今回利用を検討したきっかけです。
小鳥のひなは、歌を完成させていくときに「バブリング」という喃語(赤ちゃん特有の言葉)を話します。「うわうわうい~うい~」っていうような不明瞭な音から、だんだん大人がしゃべるような、はっきりとした歌になっていくのですが、この歌がお手本とされる歌とどれくらい似ているのか?を調べるためにAIを利用しようと考えました。
音声は、声紋を通じて視覚的に比較することができます。横軸に時間、縦軸に音の高さをとり、音の強さを色の濃さで表し、フーリエ変換した音のデータをプロットすると、声紋のパターンを視覚的に表すことができるんですね。
私達の研究では、この声紋をひなの歌と、お手本の歌の間で比較するのですが、これは、研究者間でも「それはあなたの思い込みでしょう」「似てると言ってるけど似てないよ」とか、議論になる話題でもあります。人間の耳では似てるように聞こえるんだけど、人によってはあんまり似てないようにも聞こえる、というような違いがあるんですよね。結構あいまいなんです。
HNL:
他に使おうと思っていたアプリや、比較した解析技術などはありましたか?
和多:
これまでに利用されてきた研究解析用ソフトウェアで、AVISOFTのSASLab Proっていうツールや、研究者が試行錯誤した成果などを使うことで、音が似てる似てないみたいなことは一応比べることはできるんですけども、方法をちょっと変えるだけで「あれ?」っていうような結果になるんですよね。検出感度が非常に落ちてしまうとか。
例えば、非常に短い音は、情報量がほとんどないので比較には使えません。「ピッ」という音も音の高さだけで判断してくれなくなったりしてしまって。これらは、音を視覚的に表現することで、変調の度合いなども含めて、かなり比較結果が変わってきます。
HNL:
なるほど。音を視覚的に処理したデータの比較ツールとしてEyesを使ってみよう、という流れがあったんですね。
和多:
そうですね、一回ちょっと見てもらったほうがわかりやすいかな?
音の成長を画像で判別する
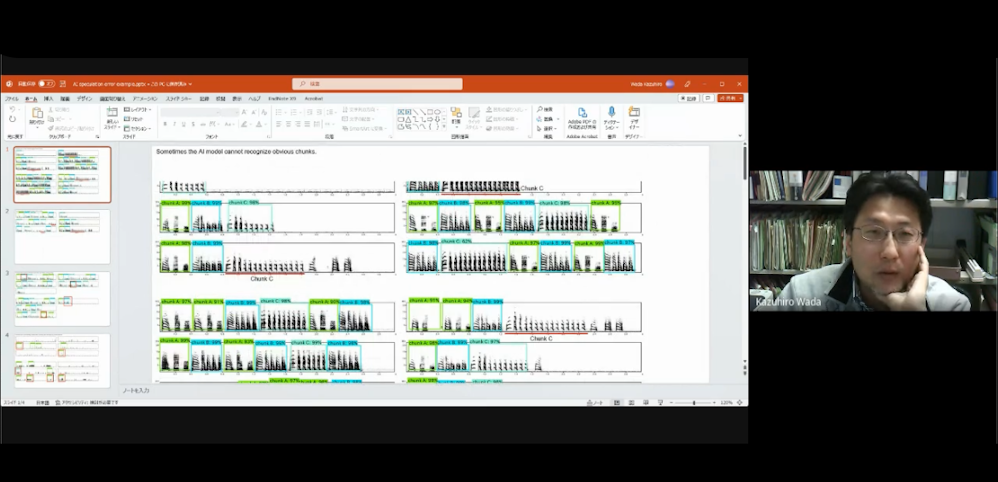
これは鳥の声紋をAIに学習させた実際の結果です。僕らはこれを見ると、だいたい鳥がどんな風にうたっているのかが想像できます。
実際に研究で何をやっているかというと、ひなに教師データとしてお手本となる親の歌を再生して聞かせています。お手本とひなの声紋情報が非常によく似てると、ちゃんと同じように認識されるんですよね。
ひとつの句をチャンク、歌全体の流れをフレーズといいます。フレーズでチャンクA→チャンクA→チャンクB→チャンクC→チャンクA→チャンクB、みたいに変化します(図1)。僕らも、ちゃんとチャンクに聞こえるし、AIもちゃんと認識してくれてるんですよね。AIが認識していない部分は、親と似ていない音を出している部分、ということになります。
僕らの一番の目的は、逆戻り。
つまり、大人になるにつれて歌が完成していく前段階において、不明瞭な音が完成に近づく中で、いつからこのチャンクAとかBとかCが作られ出すのかな?というのをAIに聞きたかったわけです。
僕らはまとまりの判定精度にずっと悩んでたんですよ。
簡単に言うと、1個1個の音に関しては何パーセント似てる、という評価ができるんですが、まとまりとして似てる・似てないの評価は非常に難しいんですね。その1個1個の間隔が変わるだけでも、既存ソフトは極端に学ばなかったりするんですが、Eyesだとそれなりに認識できている感じはします。
小鳥が大人になった歌のデータだと、既存の方法でもなんとか比較ができたんです。ただ、AIが行った結果と比較すると、AIの方が明らかに正確にやってる感じもする。 加えてそれぞれの判定精度のパーセンテージが出るのがなかなかいいなと。概ね90%くらい認識できているんですよね。
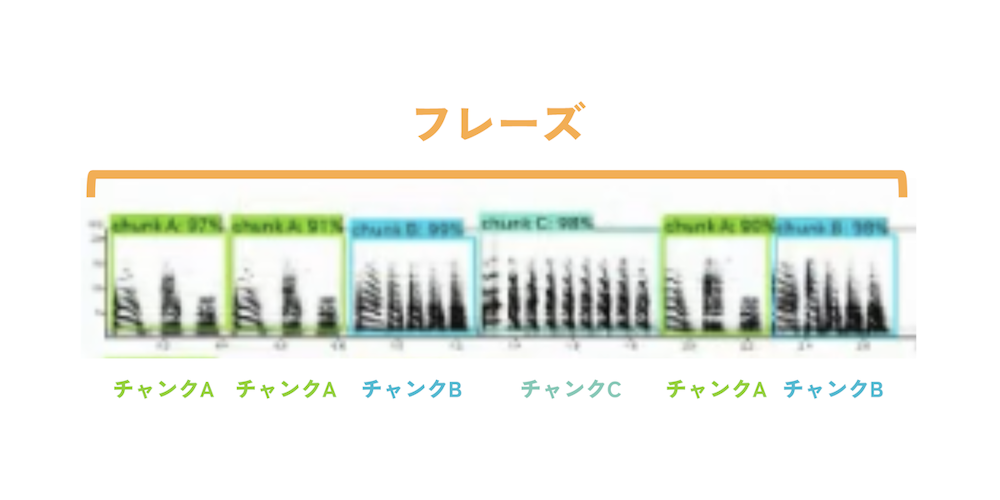
その一番いい例がチャンクCの話になります。
AIが認識しなかった部分に、チャンクCが長くなって繰り返されている部分があるんですよね。人間が見ればただの繰り返しである、とすぐに認識できるんですけど、ある程度変化が大きくなるとAIが認識できないとか、そういう点が存在します。
一方で不思議なのは、同じチャンクCの長さが違うパターンでも、少しだけ違う場合はちゃんと認識していたりするんですよね。でも、ある程度を超えるとAIが認識できなくなる。長めのチャンクの一部だけをみて認識する、というようなことがない。
完璧に判定してくれるわけではないですが、繰り返され方がある程度変わってもチャンクCと判定してくれる場合もあるので、その理由は気になるところです(図2)。
開発未経験者が1週間でAIを作れてしまった
HNL:
Eyesのことは何で知りましたか?
和多:
Eyesのことは、社長の瀬々さんが実験医学2022年7月号の記事で紹介されていたのを見かけて知りました。Eyesを使えばAI使って画像認識できるよ、と。
HNL:
ツールを生かした使い方がパッと浮かぶのは、さすがです。なかなか難しいんですよね。
ちなみにEyesを使ってアノテーション(画像データの場合、画像の中の特定の領域に対し、その部分が示す意味をラベル付けすること)やAIを作成する作業ってどなたがメインでやられてるんですか?
和多:
中国からやってきている留学生のHuくんがやってくれてます。ある程度日本語は読めるので、彼にEyesのnoteの記事を読んでもらって、デモデータで1回AIを作ってもらいました。そうしたら、1週間弱ぐらいである程度のものができちゃった、みたいな。今は他の学生にも使ってもらってます。
HNL:
Eyesは半年ぐらいお使いいただいてますが、初期と今とで使い方が変わってた点などありますか?
和多:
初期はひたすらその教師役となるデータをラベリングして、知りたい内容に合わせてAIに答えさせるっていうような形で使っていました。初めはそれなりにうまくいってるような感じがしていたんですが、明らかに似ているチャンク(ひなの声紋のまとまり)を見落としたり、スコアが低かったり、という現象が多発してきました。
教師データを増やしたりとかいろいろ条件を変えてみたのですが、どうもよくない。
チャンクBとCは区別がつくように教えているはずなのに、BにもCにも見える、とAIが判定したりだとか。あと、一番やりたかったひなのデータを判定させると、どう見ても違うチャンクと判定したり。誤答に統一性がないんですよね。
最初はアノテーションする時に同じ大きさ、同じ向きなどの対象物でなくても、つまり大きさを揃えなくても、AIは認識してくれるもの、と思っていたので、画像の大きさは適当でした。これを、教師データもテストする方の画像も、全て同じ大きさに揃えるようになってから精度が上がってきました。80%程度は正しくなってきたのでまあまあいいんじゃないのと。
HNL:
じゃあ、工夫してもうちょっと精度良くしたいよね、というような感じなんですね。
和多:
はい。
使っている中で、AIはなんでそんなふうに思うのかなぁとか考えることがあって。
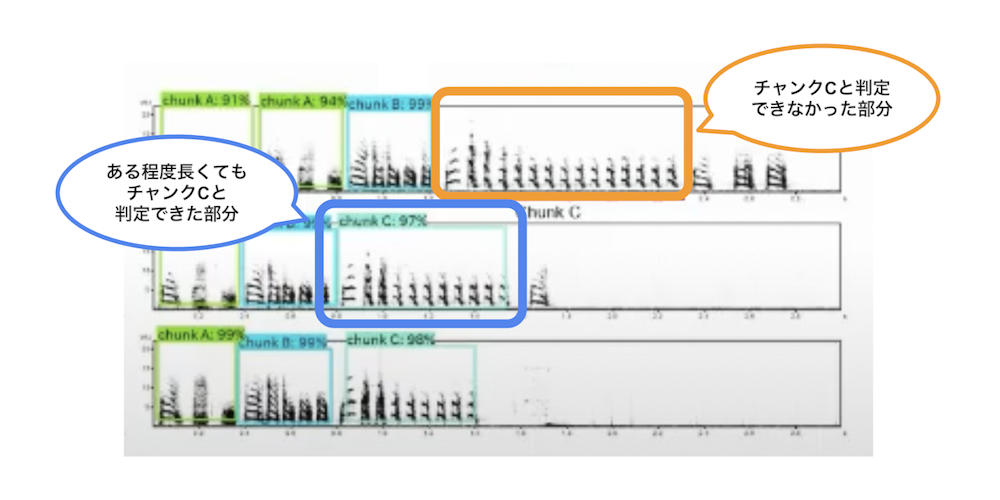
例えばなんですが、この画像の四角い枠の部分が上にちょっとずれてるんですよね。AIは画像の中のある一部分をみて、似ているかを答えてるんだろうな、とか、言っているんだろうな、と。(図3)
ツールの使い方というよりは「AIのトレーニングの仕方に気をつける必要がある」と感じています。適当な画像で適当にやればいいものではないと。特に僕らの解析に関しては。
HNL:
元のデータから解析できる状態に加工するまでに、結構手間はかかりましたか?
和多:
録音状態によっては、解析結果に影響するバックノイズが入るので、既存の音響ソフトウェアでなるべく除いてあげて、ノイズの影響がないような状態にします。そのあとに、声紋に変換したデータを使って解析しています。
AIの捉え方と人間の捉え方はずれている
HNL:
この作業はどれくらいの頻度で実施されていますか?
和多:
録音データは膨大にあるので、Huくんがほぼ毎日やってます。特に今は、条件を既に決定してデータを集めにかかってる段階なので精力的に進めています。
僕らは行動解析としての「歌の認識」を非常に重要視しているので、今のやり方が確立してきたらずっと使ってもいいかなと思っています。同じ問題を同じ領域でやっている他の研究者も同じような問題を持っています。
HNL:
今は確かにちょっと手間が多いですよね。
和多:
良い精度が得られるまでのデータ作成に関するノウハウが必要ですしね。
周波数の設定や、何秒間の画像を1枚として出力されるように設定すると精度が高くなるのか、とかそういう設定も適当だと良くなくて、違うチャンクとして判別されちゃうとか。
あと、無理に認識してほしくないところを認識してしまうところがあるんですよね。逆に、あんまり一致するところがない、と言いたい。
HNL:
ここは違うぞ!という箇所には「unknown」というようなラベルをつけるといいかもしれませんね。AIの判断基準は人間の直感と結構ずれているのは確かです。
和多:
あっている時の感覚は近いものがあるんですが、ずれた時の感覚があわないんですよねぇ・・・。
HNL:
「壊れたものを見つけたい」と言うような時とかに、壊れたものだけ覚えさせても、なんだかいい結果にならない、ということはありがちです。なので、壊れたものを見つけたい時は、壊れているものと、壊れていないものの両方を教えてあげると、AIは両者の差をうまいこと判断してくれるので、「これは壊れているものなんだな」と読み取ってくれるようになったりします。
和多:
じゃあ、これから「unknown」ラベルのアノテーションをいっぱい作っていくと、あやふやなものは選ばないようになるかもしれないですね。
HNL:
選んでほしくない対象がある場合、それをAIに教えてあげることは、精度をあげるひとつの手になります。
和多:
ラベルの重なりの問題はどうしたらいいんですかね?重なった場合は、スコアの高い方を選ぶようにはしているんですけど。
HNL:
AIアノテーションの機能を使うと、何%以上の場合にラベル付けしてほしい、というような感じでしきい値を変えられるんですね。通常だと50%以上だと全てについてしまうので、しきい値がどれぐらいの設定だと重ならないで判定できるか?をお試しいただくとよいかもしれません。
別のラベルの重なりが邪魔という問題について、完全に解消するのは難しいかもしれませんが、AIアノテーション機能で判定をしてほしい画像を別タスクとして作ってみてください。実際に判定する時にAIアノテーションで作ったモデルを選択していただくと、判定時のしきい値の設定ができます。しきい値を調整することで、90%以上しか出さないとか、80%以上までは出すとか設定すると、見やすい結果画像が得られるようになるかもしれません。
和多:
このチャンクCなんかも、もしかして短いやつも、長いやつもトレーニングさせることで精度が高くなるのかもしれませんね。
人間の目による判断にはバイアスがあるんですが、Huくんが人の目で判定したラベルの分布傾向は、AIが判定したラベルの分布と結構似てくるんですよね。複数の鳥のデータで調査しても同様の傾向がみられるので、結果は許容範囲かなと。
そういう意味では、当初の目的は達しつつあるかなと思っています。
HNL:
ここまでで、Eyesでやりたかった一番の目的が「AIの判定と人間の目による判定が似た結果になることを確認すること」とお伺いしましたが、その次の目的は想定されていましたか?
和多:
できればシステム側で勝手にラベリングしてくれるといいんだけどな、ということですよね。
Eyesに合うようにデータを準備するとより正確な結果が出るので、データプレパレーション(データ分析の前に行うデータを分析できる形に変換すること)しなくてはならない、という手間がめんどくさいな、と感じています。
精度をあげるために今もいろいろデータ形式を変えながら試しているのですが、画像は白黒よりもカラーのほうが精度が上がる、みたいなことってあったりするんですか?
HNL:
場合による、といった回答となってしまうのですが。
カラーの場合、画像の持つ情報量が増えるので、理論的には精度が高くなる可能性があるのですが、白黒画像の方が被写体の傾向をつかみやすい場合もあります。色味がバラバラすぎると傾向がつかみにくくなる場合もあるので、そこはトライアンドエラーでそれぞれの精度を比較するのがよいかもしれません。
和多:
あと、将来的にやりたいのは「判定の細分化」です。
今、いくつかの波形データをひとかたまりとして「チャンクA」と判定しているのですが、チャンクAを構成する要素を「チャンクA-1」「チャンクA-2」「チャンクA-3」と細分化された要素として判定したい、加えて、チャンクA-1・A-2・A-3が順番通りに並んでいるか、A-1・A-2・A-3の要素がどのように繰り返されて出現しているのか、という情報が得られるようになると良いな、と考えています。
これらの細かいパーツがかたまることでクラスターになってるんだっていうことを言えると非常にいいなと。
HNL:
このデータはもともと「音」なので、系列だった並びになってると思うんですけれど、音を画像としてAIが認識した場合、記憶した画像単体の「形」自体を学習していくんですよね。なので、この画像が出たから次はこれ、みたいな、画像と時系列的な情報を掛け合わせた予測となるので、技術的にかなり難易度が上がりそうです。
画像によるAIの予測では、指定した領域が似ているか否か?の判定が行われているので、チャンクの出現状況を加味するのであれば、フレーズの前後の領域を入れた形で、教えたほうがいいのかもしれません。
和多:
対象物の位置情報を元に、近くに出現する可能性の高い要素を予測できたりするといいのかもしれませんね。
HNL:
今日はポジティブな話も含めて、いろいろと面白いお話をお聞かせいただき、本当にありがとうございました!
あとがき
今回は北海道大学の和多先生に、研究のご紹介とEyesをどのように使用されているかをお伺いしました。小鳥も人間と同じように、鳴き声を学んでいく途中の段階があるんですね。物体検知AIと聞くと色のある写真を利用するイメージがありましたが、グラフに対しても活用できることには驚きました。また、恣意的ではなく、客観的な判断基準が必要な際にAIを用いるのは素晴らしい利用方法だなと感じました。
Humanome Eyesは無料でお試しいただけます
Humanome Eyesは、商品検査や成熟度検査などの業務目的だけではなく、教育・研究用としても広くご利用いただけます。
本商品の購入、本商品に関するご質問・ご相談等につきましては、以下のフォームよりお気軽にお問い合わせ下さい。



