
CatDataマニュアル 目次
データの可視化・分析
データを選択したり、分布を可視化したりすることで、 データからストーリーを考える分析が可能です
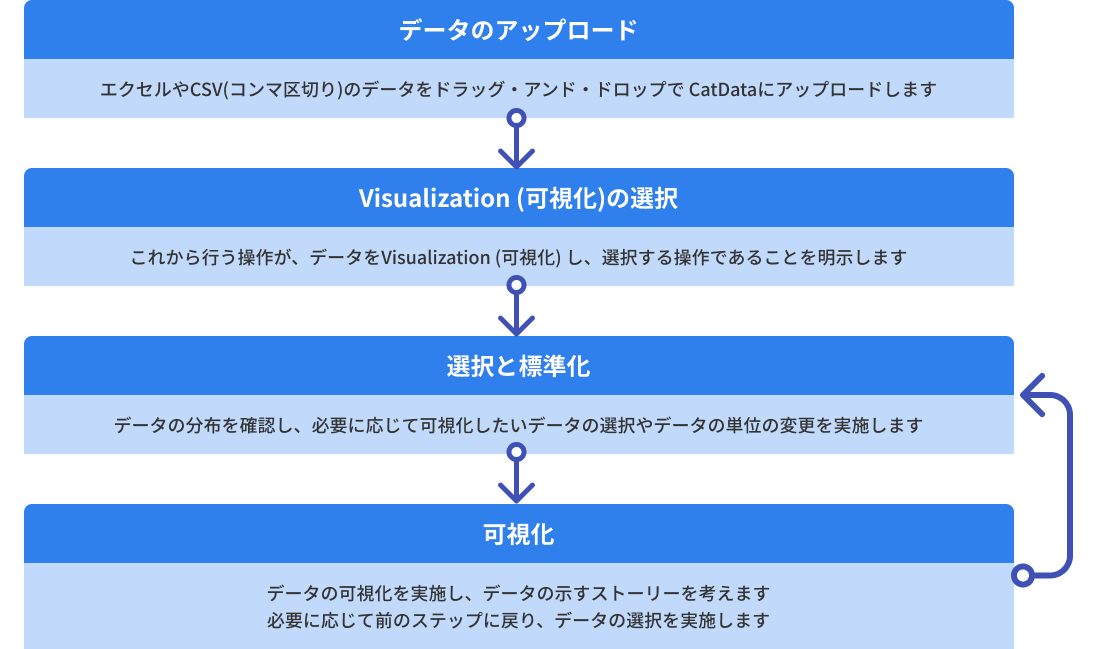
データの可視化・分析の流れ
サンプルデータを用いた解析の目的
- あやめ(iris)120個体の がくの⻑さ、がくの幅、花弁の⻑さ、花弁の幅、種類(ここでは、0、1、2 とします)の情報を可視化します。
- 花弁の⻑さが特定の条件の個体を除去する方法を紹介します。
- 花弁の⻑さ・幅の関係を可視化し、あやめの種類との関係を見出します。
データのアップロード
「テーブルの新規作成」をクリックし、ファイルアップロード画面を開きます
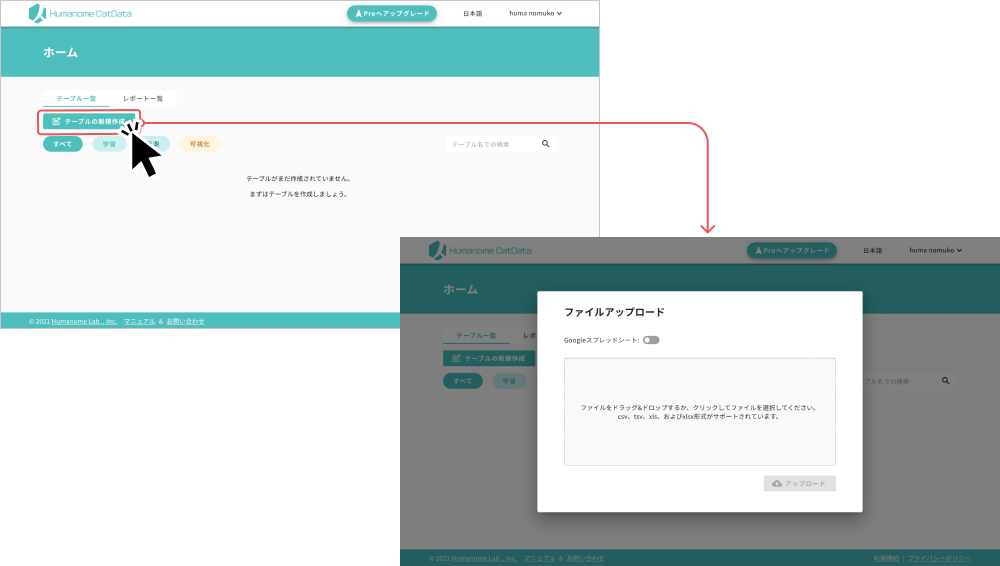
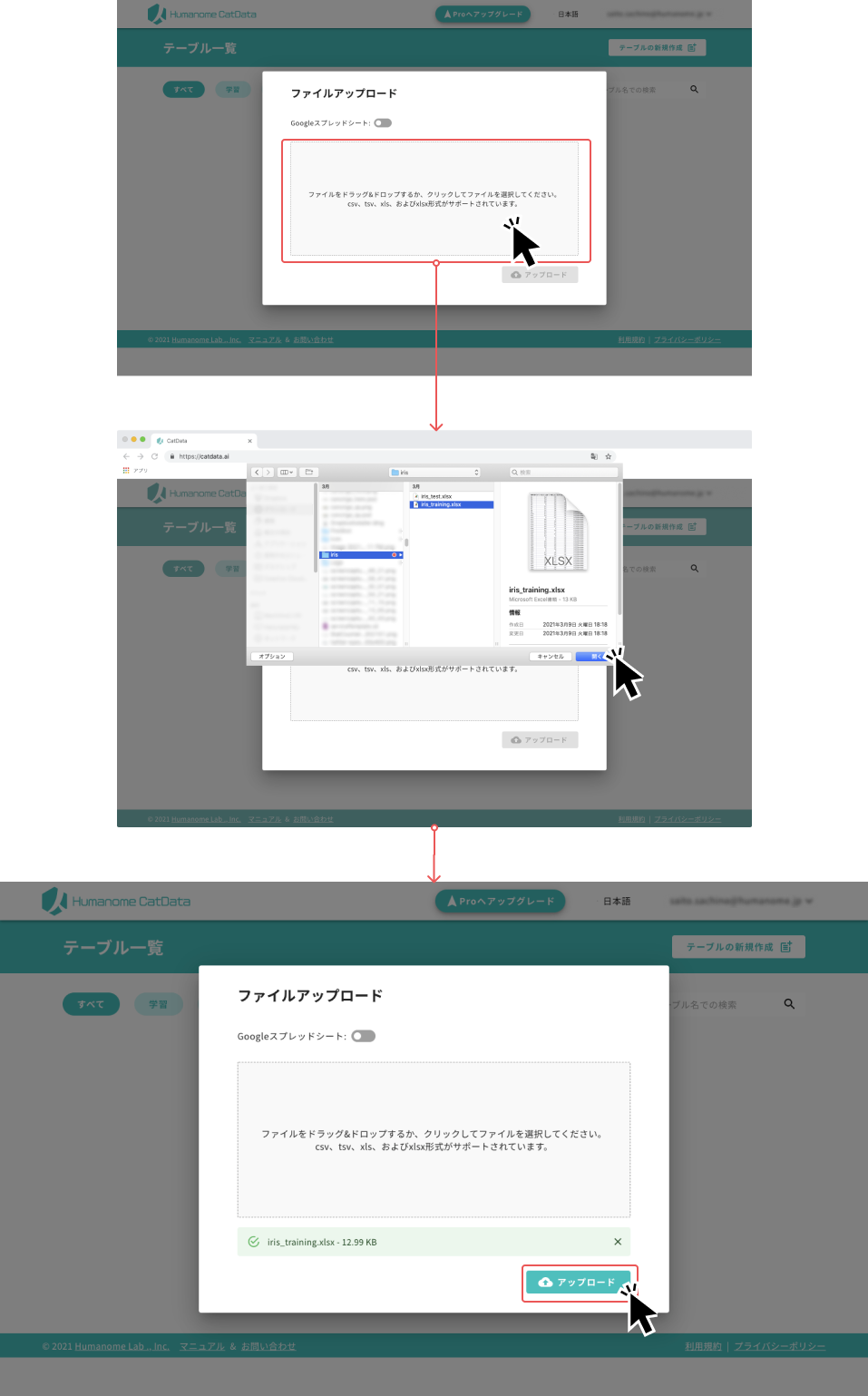
ファイルアップロードエリアでiris_training.xlsx を選択し、アップロードボタンをクリックしてください
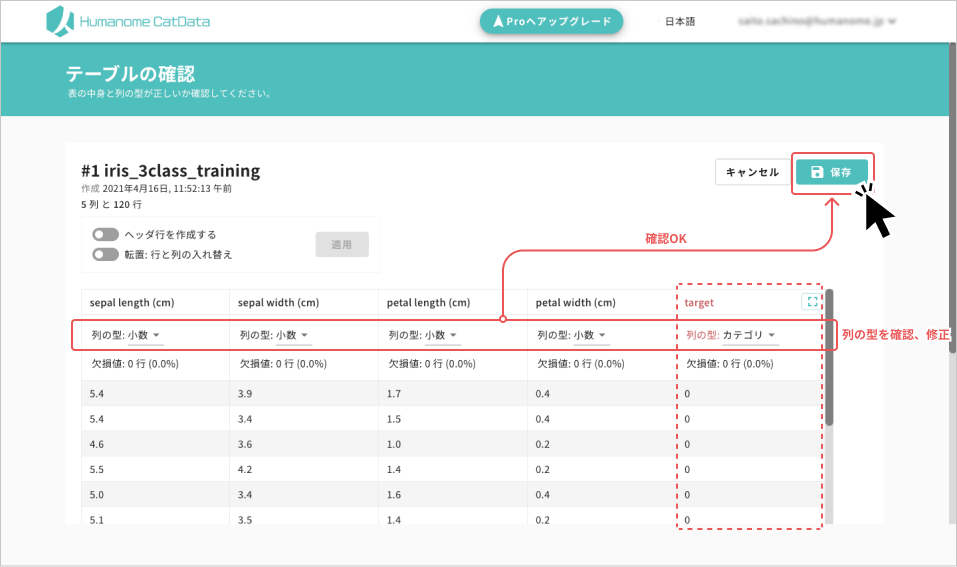
アップロードされたデータについて確認する
- アップロードしたデータが間違っていないか確認をします。
- 特に、列名と数値に ずれが無いかどうか、各列の型(*)が意図したものか確認してください。
特に赤字の列は、型を自動で判別していたり、欠損値が多い列なので、注意深く確認してください。- 赤字の列:型が自動で変更された列、もしくは欠損値が多い列です
(*)数字や文字列のこと。CatDataは自動で判別します。 意図したものと間違っている場合、修正してください。 ここで決定した型は、後で修正できません。
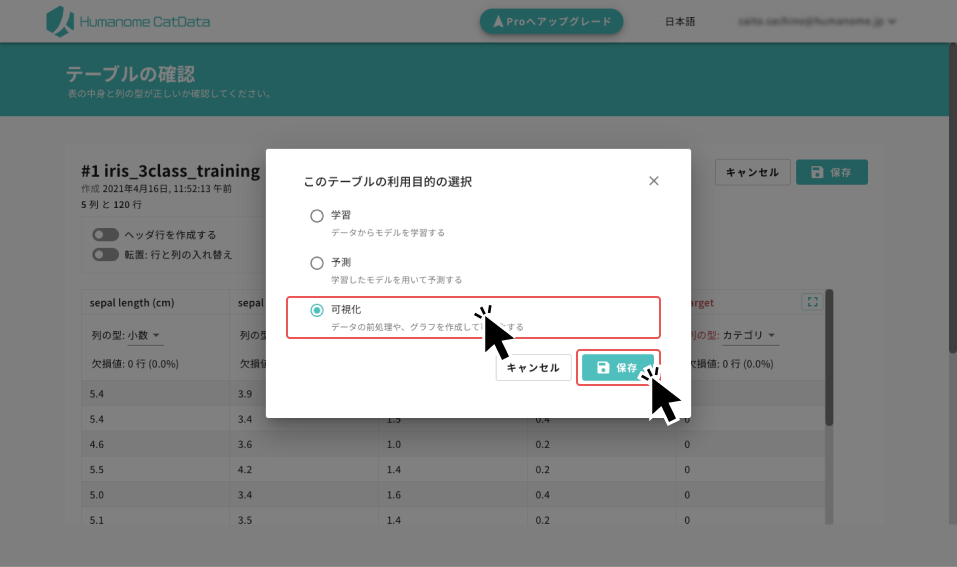
テーブルの利用目的として、可視化(Visualization)を選択する
- データを保存すると「このテーブルの利用目的」を選択するモーダルウィンドウが開きます。アップロードしたテーブルの利用目的を選択します
- 機械学習を実施する前に、データの分布を見て、データの様子を知るために「可視化」を選択します
- 可視化をすることで、AI作成が容易なデータか、あるいは、難しそうか、あたりをつけます
データの前処理を行うページへ移動する
意図しないデータの混入や、値に偏りが無いかどうかを確認します
選択と標準化
前処理:データの選択と正規化 (*)を実施する
(*)正規化:平均0、分散1になるように単位の変更を実施すること。
大きく単位が異なる変数が存在する場合に、 学習が難しくなることがあるため、必要に応じて実施します。
特に必要がなければ、このステップは省略して可視化に進めます
下の図は、花びらの⻑さ (cm) が短いもの(破線で囲ったところ)を削除する操作(アクション)の作成例です。
花びらの⻑さの分布を見ると、明らかに短い集団が存在するので、除いてみました。
- 「花弁の長さ (cm)」項目をクリックして、項目詳細ページへ遷移します
- 項目詳細ページで、花弁の値が明らかに短い集団を取り除きます。
グラフ下にある「最小値」の数値を2.5に変更し、「追加」ボタンをクリックしてアクションを追加します - 「前処理 1/2: アクションセットの編集」ページにて、アクションが追加されていることを確認します。問題なければ「適用」ボタンのクリックし、追加したアクションを適用します
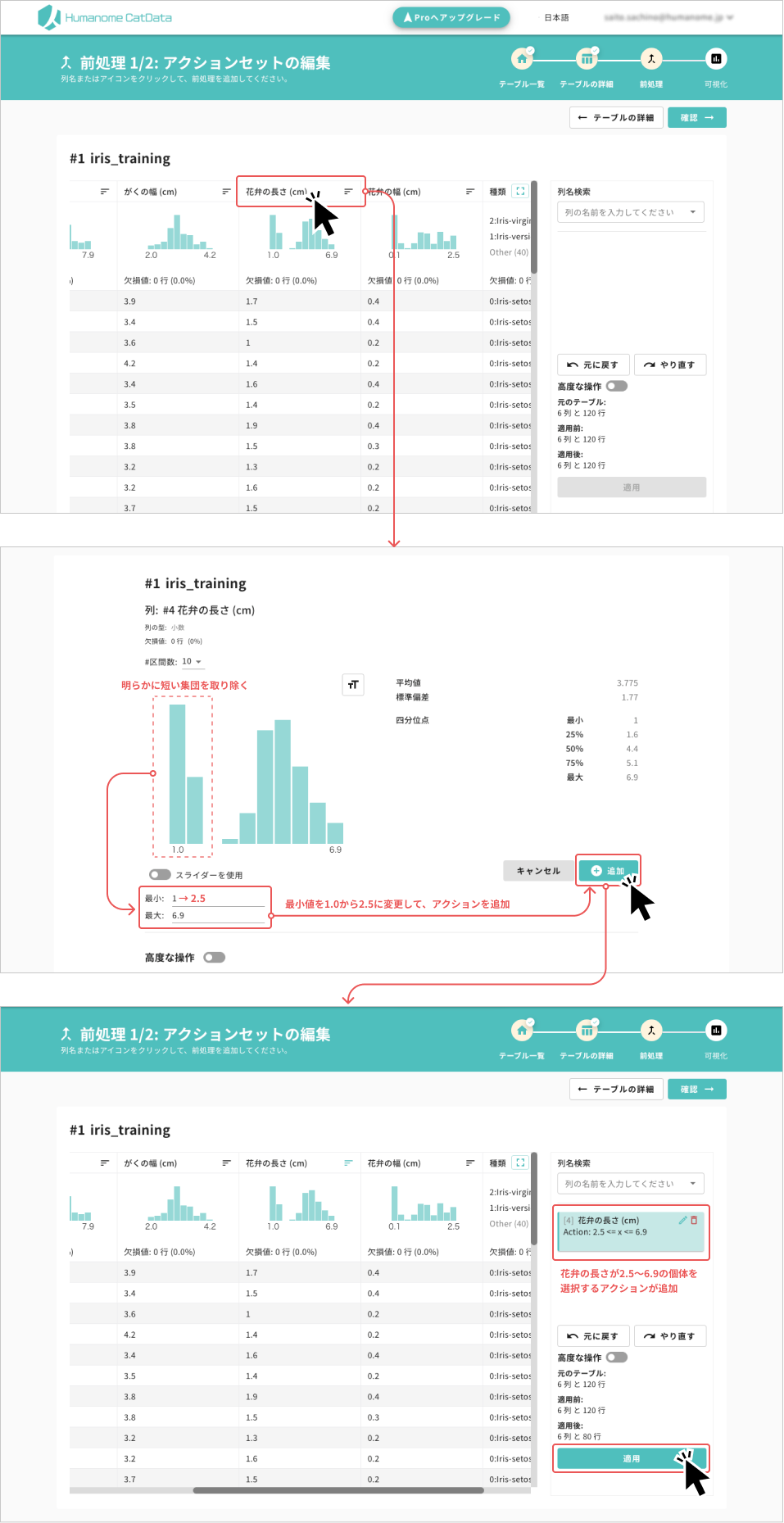
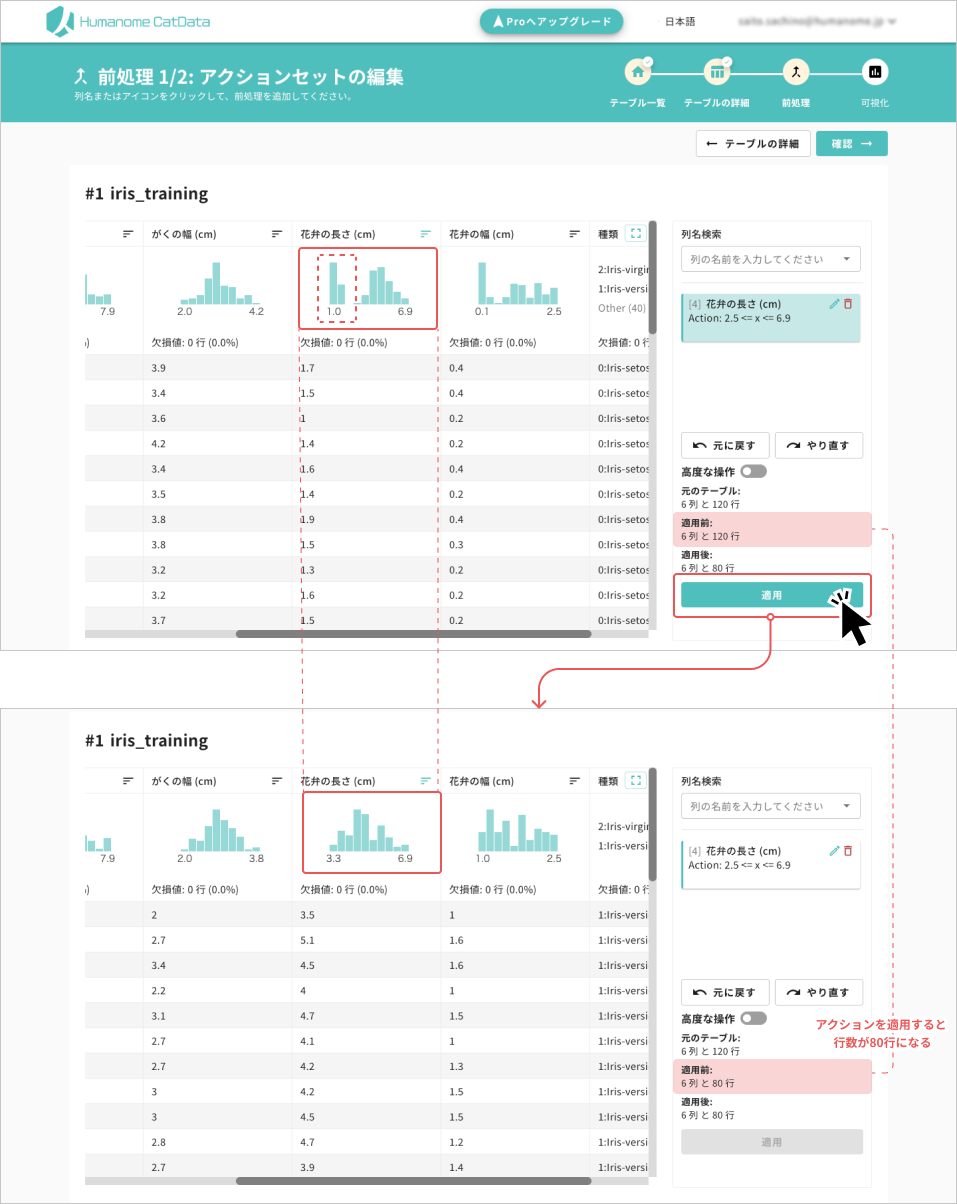
- アクションが追加されただけでは、その処理は適用されません。「適用」ボタンのクリックで、追加したアクションを適用します。
- 下の例では、全120個体中、花弁の⻑さ (cm) の値が2.5以上の80サンプルに絞ったので、連動してデータ全体の分布が変わっています。サンプル数(行数)の変化は右下の窓で確認できます。
データの選択と正規化が終わったら、データの可視化を実施
前処理終了後、問題なければ可視化に進みます。
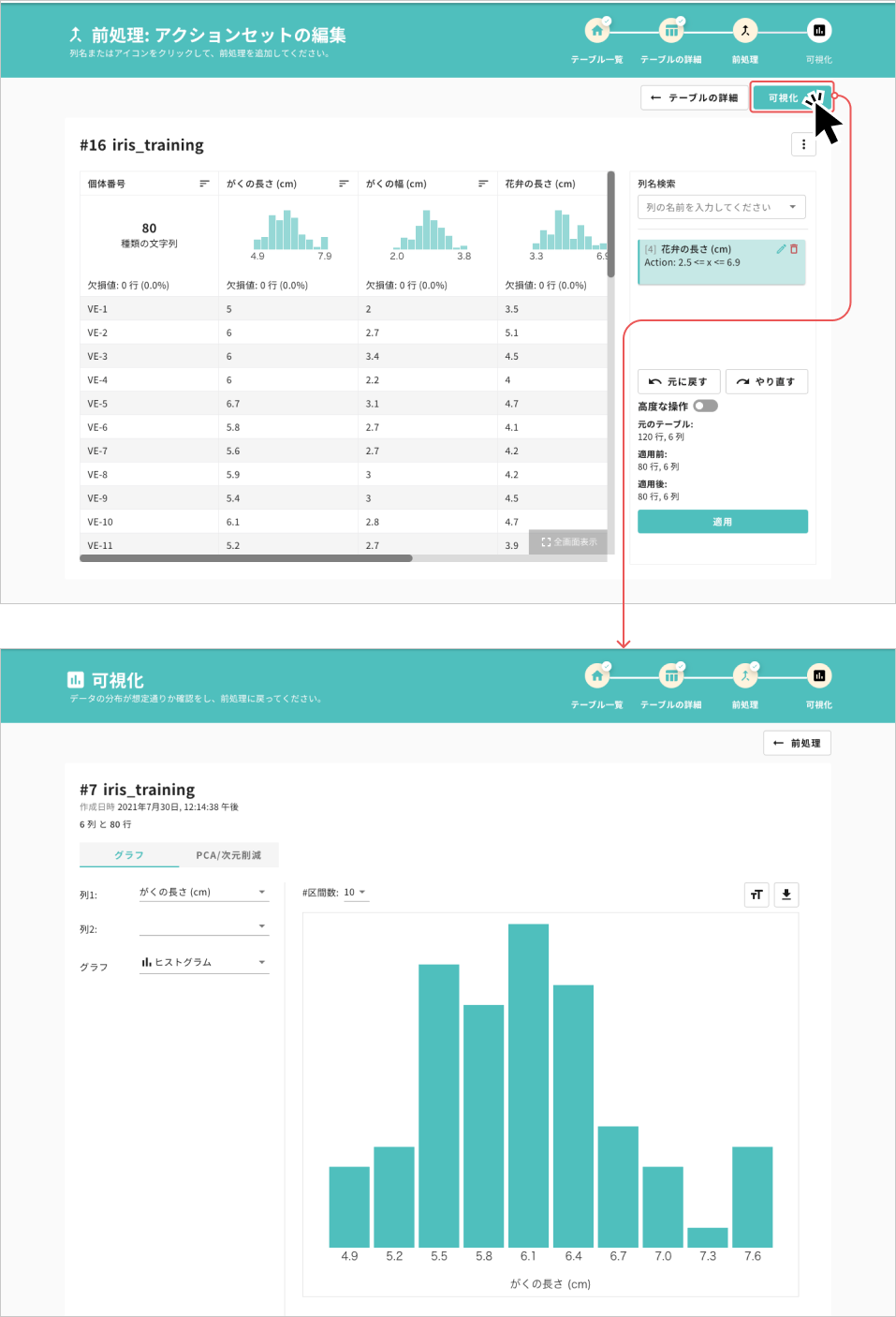
データの可視化を実施
- 列ごとの分布や、列の間の関係を可視化します。はじめは「列の分布」グラフが現れます
- 列2に別の列を指定することで散布図などの分布が描画できます
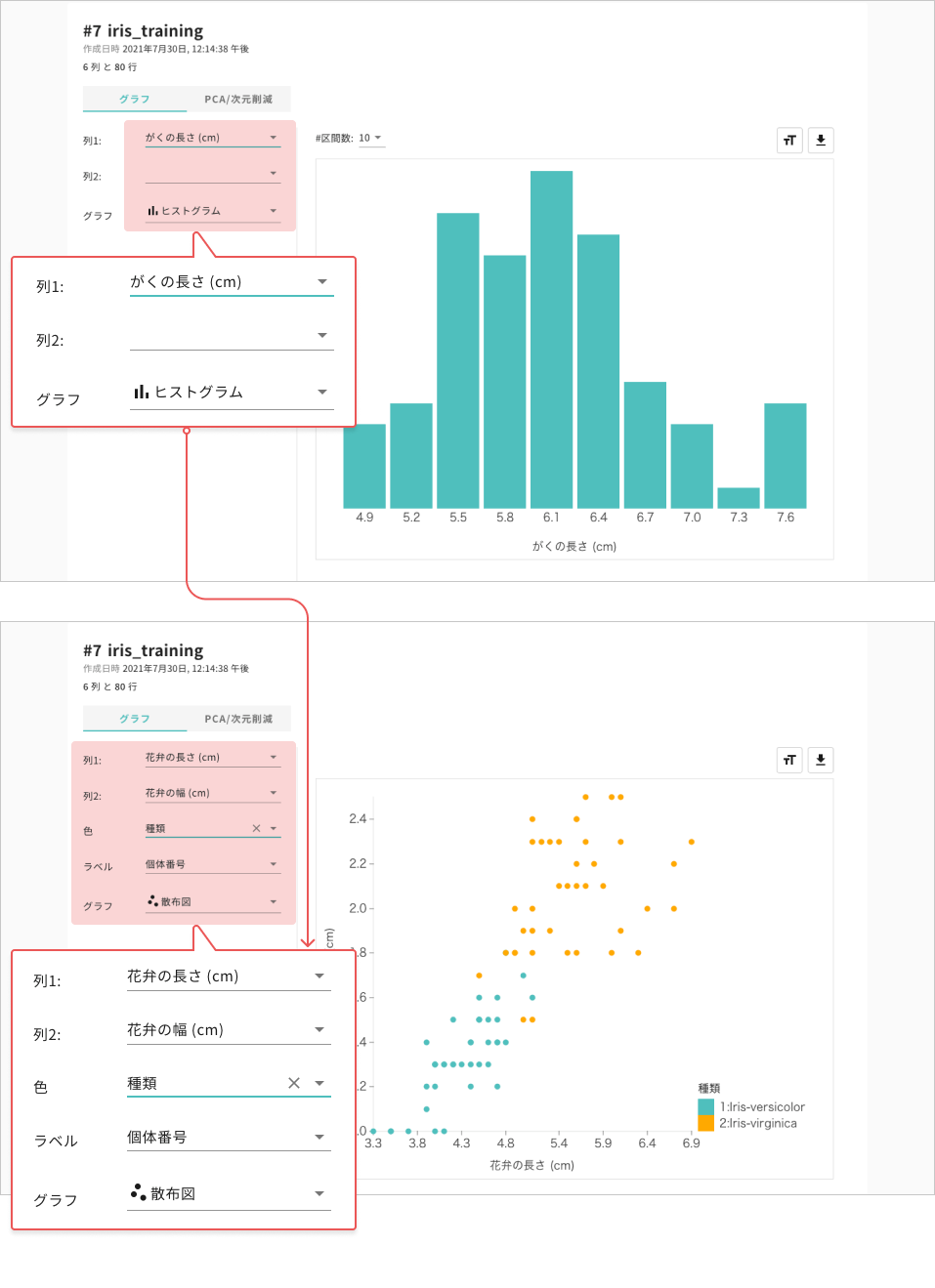
散布図を描画の上、色で「種類」を指定すると、種類別(緑:1、⻩色:2)に分布が異なることがわかり、品種の区別をする機械学習モデルは比較的容易に作成できると考えられます(上図参照)。
一方、種ごとに分布がまとまっておらず混在している場合には、モデル作成も困難なことが多くなります
あやめのデータを用いた可視化の利用例
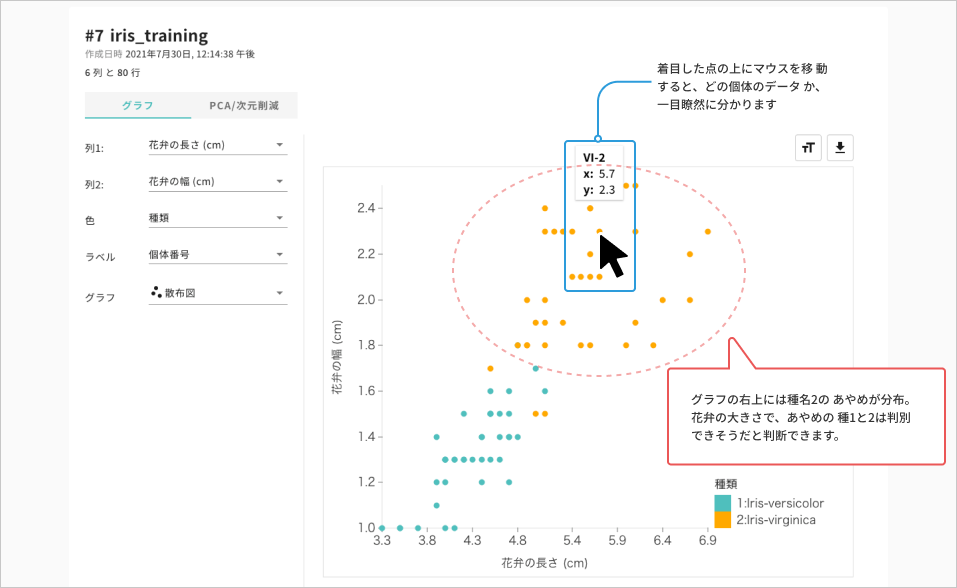
- 列1:花弁の⻑さ (cm)
- 着目した点にマウスを重ねると情報が表示され、どの個体のデータなのかが一見して分かります
- 列2:花弁の幅 (cm)
- 色:種名を選択
- ラベル:個体番号
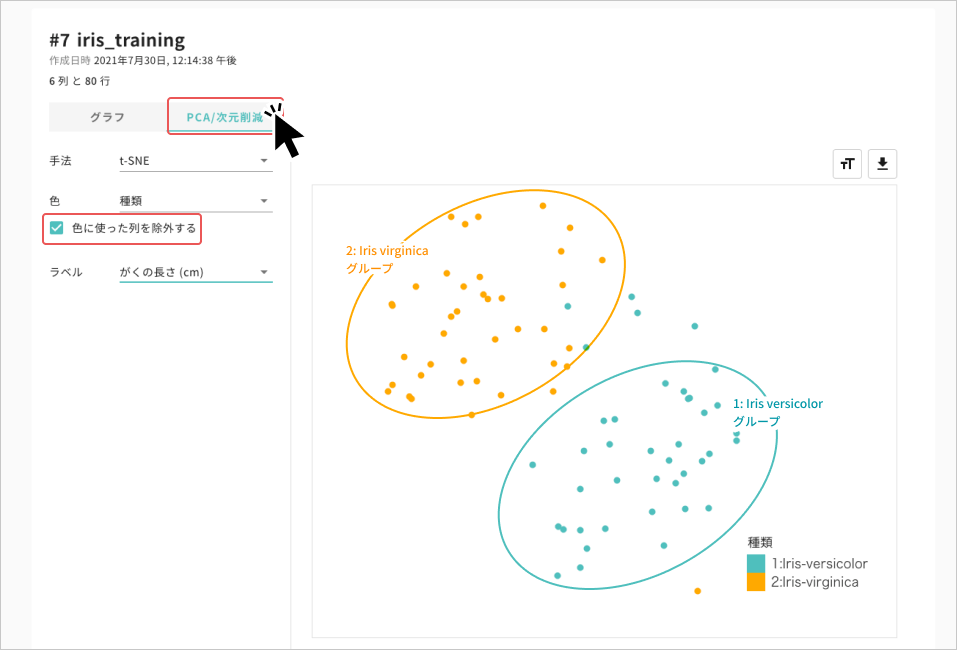
2変数では区別がつかず、3変数以上の関係を見る必要がある場合もあります。この時には次元削減が有用です
図は、「色に使った列を除外する」機能を利用し、がくの⻑さ/がくの幅/花弁の⻑さ/花弁の幅 の情報を次元削減した結果です。
あやめの種類で配色しました。
あやめの種類ごとにグループが分かれています。がくと花弁の大きさは、種類により異なる傾向があることがわかります。
次は「AIモデル(機械学習モデル)の作成」です。
CatDataマニュアル 目次
- 解析準備・CatDataの登録
- データの可視化・分析
- AIモデル(機械学習モデル)の作成
\商品ページはこちら/

